The Ingestion and Fusion Pipeline
To ensure system resilience and scalability, the transition from raw model output to searchable intelligence follows a decoupled, three-stage process:
1. Transactional Persistence
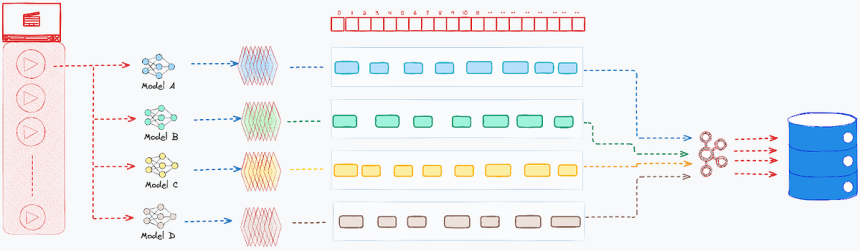
Raw annotations are ingested via high-availability pipelines and stored in our annotation service, which leverages Apache Cassandra for distributed storage. This stage strictly prioritizes data integrity and high-speed write throughput, guaranteeing that every piece of model output is safely captured.
{
"type": "SCENE_SEARCH",
"time_range": {
"start_time_ns": 4000000000,
"end_time_ns": 9000000000
},
"embedding_vector": [
-0.036, -0.33, -0.29 ...
],
"label": "kitchen",
"confidence_score": 0.72
}
Figure 2: Sample Scene Search Model Annotation Output
2. Offline Data Fusion
Once the annotation service securely persists the raw data, the system publishes an event via Apache Kafka to trigger an asynchronous processing job. Serving as the architecture’s central logic layer, this offline pipeline handles the heavy computational lifting out-of-band. It performs precise temporal intersections, fusing overlapping annotations from disparate models into cohesive, unified records that empower complex, multi-dimensional queries.
Cleanly decoupling these intensive processing tasks from the ingestion pipeline guarantees that complex data intersections never bottleneck real-time intake. As a result, the system maintains maximum uptime and peak responsiveness, even when processing the massive scale of the Netflix media catalog.
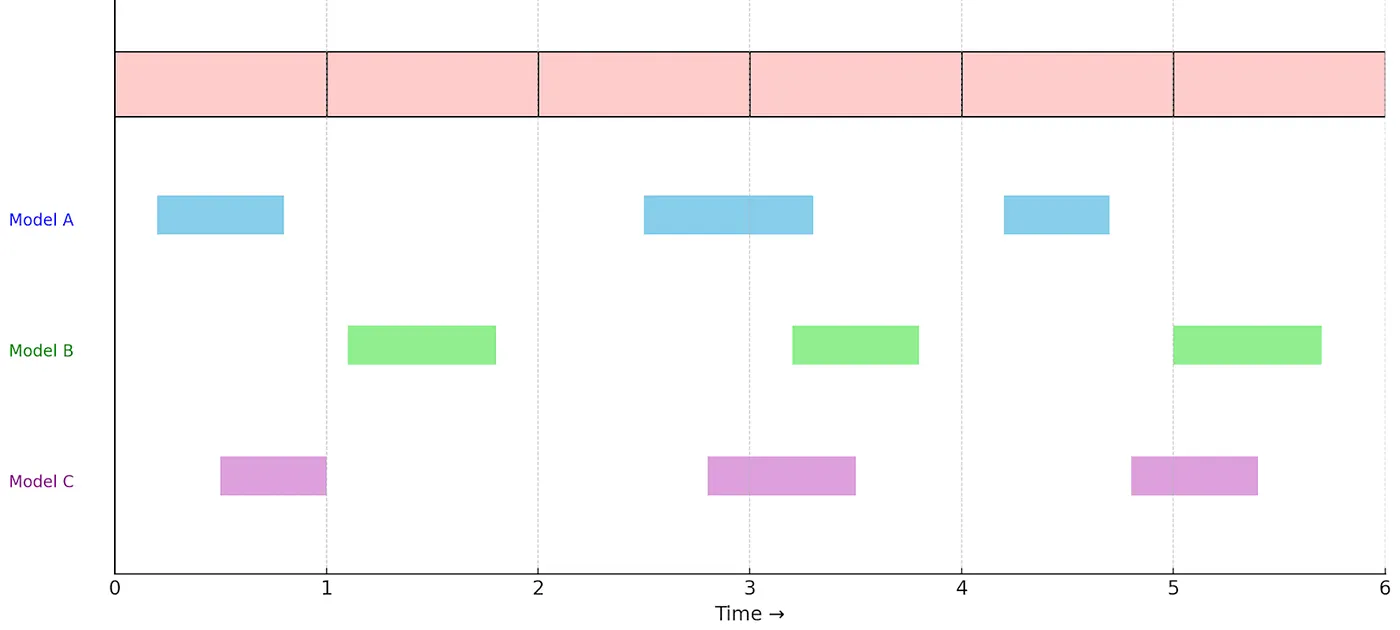
To achieve this intersection at scale, the offline pipeline normalizes disparate model outputs by mapping them into fixed-size temporal buckets (one-second intervals). This discretization process unfolds in three steps:
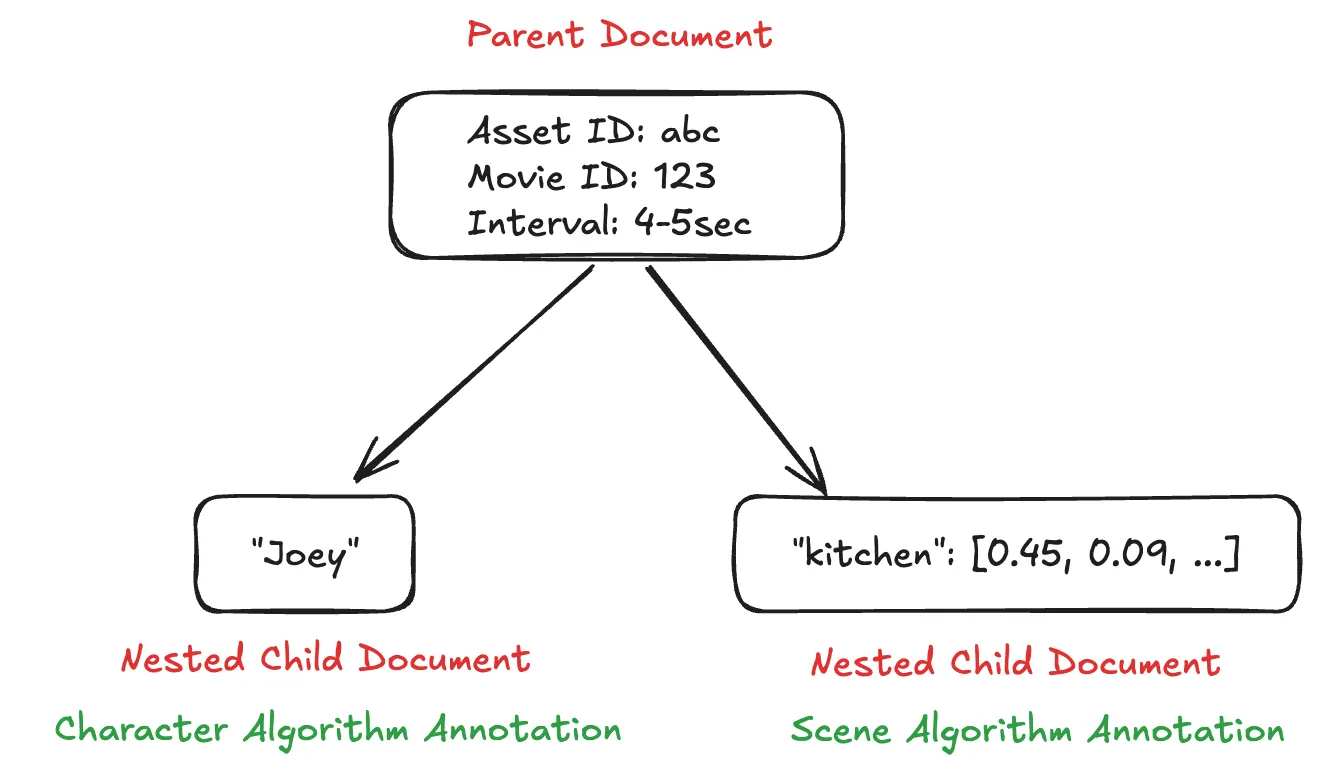
- Bucket Mapping: Continuous detections are segmented into discrete intervals. For example, if a model detects a character “Joey” from seconds 2 through 8, the pipeline maps this continuous span of frames into seven distinct one-second buckets.
- Annotation Intersection: When multiple models generate annotations for the exact same temporal bucket, such as character recognition “Joey” and scene detection “kitchen” overlapping in second 4, the system fuses them into a single, comprehensive record.
- Optimized Persistence: These newly enriched records are written back to Cassandra as distinct entities. This creates a highly optimized, second-by-second index of multi-modal intersections, perfectly associating every fused annotation with its source asset.
The following record shows the overlap of the character “Joey” and scene “kitchen” annotations during a 4 to 5 second window in a video asset:
{
"associated_ids": {
"MOVIE_ID": "81686010",
"ASSET_ID": "01325120–7482–11ef-b66f-0eb58bc8a0ad"
},
"time_bucket_start_ns": 4000000000,
"time_bucket_end_ns": 5000000000,
"source_annotations": [
{
"annotation_id": "7f5959b4–5ec7–11f0-b475–122953903c43",
"annotation_type": "CHARACTER_SEARCH",
"label": "Joey",
"time_range": {
"start_time_ns": 2000000000,
"end_time_ns": 8000000000
}
},
{
"annotation_id": "c9d59338–842c-11f0–91de-12433798cf4d",
"annotation_type": "SCENE_SEARCH",
"time_range": {
"start_time_ns": 4000000000,
"end_time_ns": 9000000000
},
"label": "kitchen",
"embedding_vector": [
0.9001, 0.00123 ....
]
}
]
}
Figure 4: Sample Intersection Record For Character + Scene Search
3. Indexing for Real Time Search
Once the enriched temporal buckets are securely persisted in Cassandra, a subsequent event triggers their ingestion into Elasticsearch.
To guarantee absolute data consistency, the pipeline executes upsert operations using a composite key (asset ID + time bucket) as the unique document identifier. If a temporal bucket already exists for a specific second of video, perhaps populated by an earlier model run, the system intelligently updates the existing record rather than generating a duplicate. This mechanism establishes a single, unified source of truth for every second of footage.
Get Netflix Technology Blog’s stories in your inbox
Join Medium for free to get updates from this writer.
Architecturally, the pipeline structures each temporal bucket as a nested document. The root level captures the overarching asset context, while associated child documents house the specific, multi-modal annotation data. This hierarchical data model is precisely what empowers users to execute highly efficient, cross-annotation queries at scale.